

prince of aden
الإدارة العامة و مسؤول منتدى العروض المجانية
طاقم الإدارة
★★ نجم المنتدى ★★
نجم الشهر
كبار الشخصيات
- إنضم
- 30 نوفمبر 2010
- المشاركات
- 46,624
- مستوى التفاعل
- 61,489
- النقاط
- 15,330



غير متصل
من فضلك قم بتحديث الصفحة لمشاهدة المحتوى المخفي


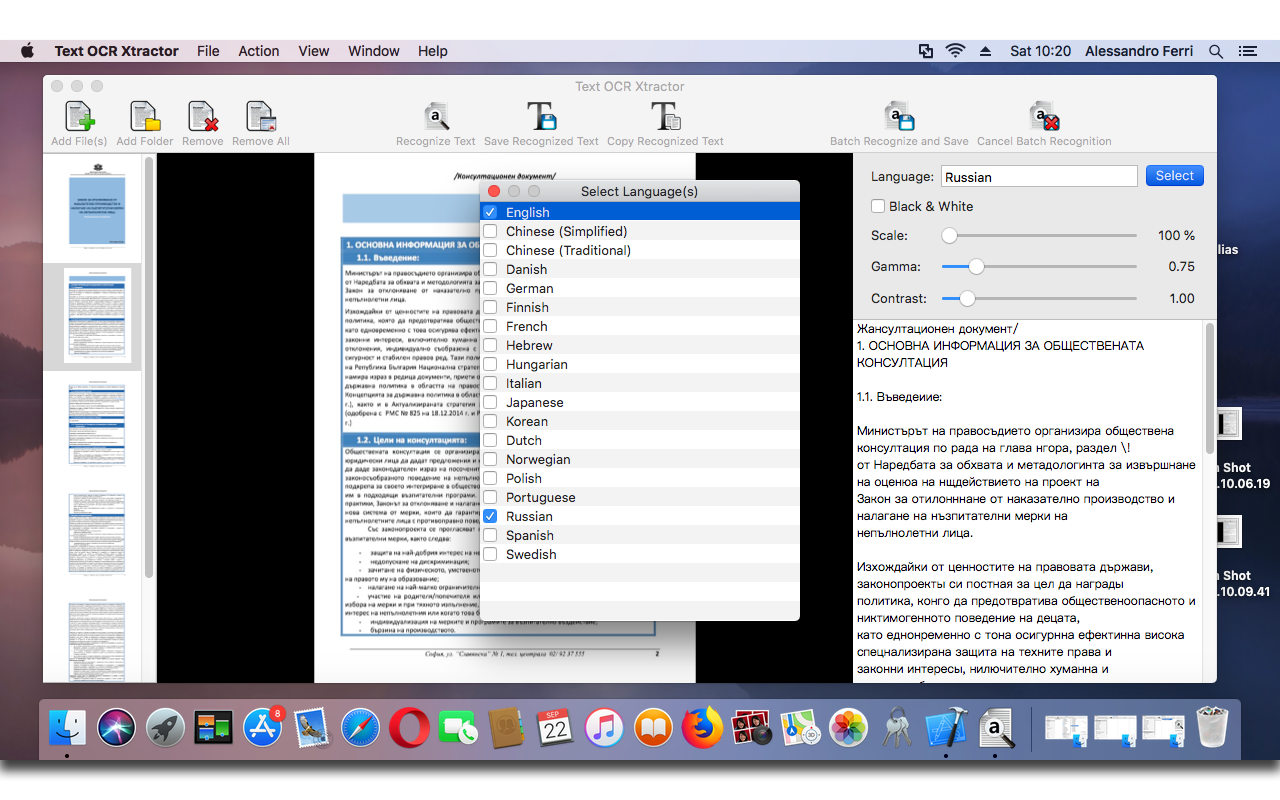
PDF Text OCR Xtractor 1.8.5
استخراج النص من ملفات PDF وجميع أنواع تنسيقات الصور الشائعة.
يعد PDF Text OCR Xtractor مثاليًا لاستخراج النص من ملفات PDF وجميع أنواع تنسيقات الصور الشائعة ، مثل PNG و JPG و BMP و TIFF. يستخدم برنامج PDF Text OCR Xtractor تقنية Tesseract OCR. ربما يكون Tesseract هو أقوى برامج OCR وأكثرها تقدمًا ، وهنا السبب: أولاً وقبل كل شيء ، القليل من التاريخ. تم تطويره بواسطة HP في عام 1994 ، ولكن سرعان ما أصدرته الشركة بموجب ترخيص Apache لتطوير المصادر المفتوحة. في عام 2006 ، استحوذت Google على المشروع ورعت المطورين للعمل على Tesseract. تقدم سريعًا الآن وأصبح Tesseract أقوى محرك OCR يستخدم التعلم العميق لاستخراج النصوص من الصور (BMP ، PNG ، JPEG ، TIFF ، إلخ) وملفات PDF. يدعم PDF Text OCR Xtractor أكثر من 20 لغة مختلفة ويتيح لك تعيين معلمات معالجة مخصصة لملفات / صور المصدر ، مثل التنعيم وتعديل DPI ، وزيادة التباين ، وغيرها من الحيل المفيدة ، قبل تحليلها. يتميز PDF Text OCR Xtractor بدقة عالية وسيحصل على أي صورة أو ملف PDF لديك في نص قابل للتحرير. التحويل من صورة إلى نص سريع.
الخصائص الرئيسية : 1
. استخدام أفضل تقنيات التعرف الضوئي على الحروف المتاحة. 2. دعم أكثر من 20 لغة مختلفة. 3. تحويلات صور مفيدة لتعزيز الدقة في المستندات الصعبة. ميزات اضافية: 1. أرخص واجهة مستخدم رسومية لمحرك Tesseract يمكنك أن تجدها! 2. دعم ملفات PDF وجميع تنسيقات الصور الشائعة مثل PNG و JPG و BMP.
متطلبات النظام : Windows 7 / 8.1 / 10 (x32 / x64)
الناشر: برنامج PCWinSoft
الصفحة الرئيسية:
يجب عليك
تسجيل الدخول
او
تسجيل لمشاهدة الرابط المخفي
حجم الملف: 131 ميجابايت
تفاصيل الترخيص :مدى الحياة

يجب عليك
تسجيل الدخول
او
تسجيل لمشاهدة الرابط المخفي














